OVRL-V2: A simple state-of-art baseline for ImageNav and ObjectNav
Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya, Naoki Yokoyama, Alexei Baevski, Zsolt Kira, Oleksandr Maksymets, Dhruv Batra
March 2023
Abstract
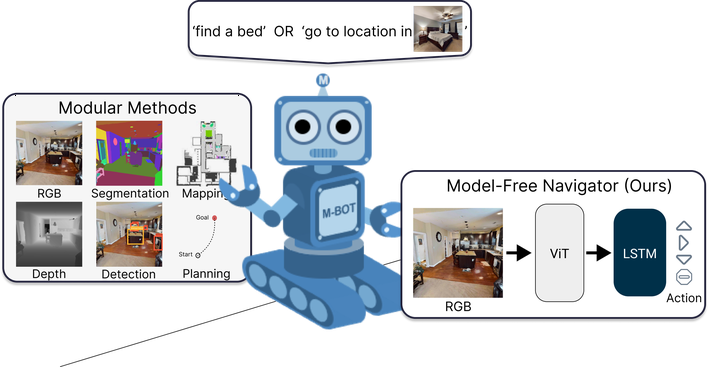
We present a single neural network architecture composed of task-agnostic components (ViTs, convolutions, and LSTMs) that achieves state-of-art results on both the ImageNav (“go to location in ") and ObjectNav (“find a chair”) tasks without any task-specific modules like object detection, segmentation, mapping, or planning modules. Such general-purpose methods offer advantages of simplicity in design, positive scaling with available compute, and versatile applicability to multiple tasks. Our work builds upon the recent success of self-supervised learning (SSL) for pre-training vision transformers (ViT). However, while the training recipes for convolutional networks are mature and robust, the recipes for ViTs are contingent and brittle, and in the case of ViTs for visual navigation, yet to be fully discovered. Specifically, we find that vanilla ViTs do not outperform ResNets on visual navigation. We propose the use of a compression layer operating over ViT patch representations to preserve spatial information along with policy training improvements. These improvements allow us to demonstrate positive scaling laws for the first time in visual navigation tasks. Consequently, our model advances state-of-the-art performance on ImageNav from 54.2% to 82.0% success and performs competitively against concurrent state-of-art on ObjectNav with success rate of 64.0% vs. 65.0%. Overall, this work does not present a fundamentally new approach, but rather recommendations for training a general-purpose architecture that achieves state-of-art performance today and could serve as a strong baseline for future methods.
Click the Cite button above to view the bibtex.

Ph.D. Student at Georgia Tech
My research interests include Multimodal Reasoning, Agents, and Embodied AI.
 Offline Visual Representation Learning v2
Offline Visual Representation Learning v2